Digital Archives: Data Migration
The Austin History Center (AHC) is in the process of implementing Preservica digital preservation software, with plans for ArchivesSpace integration. In addition to functioning as a repository, Preservica provides public access for digitized and born-digital items from the AHC’s collections.
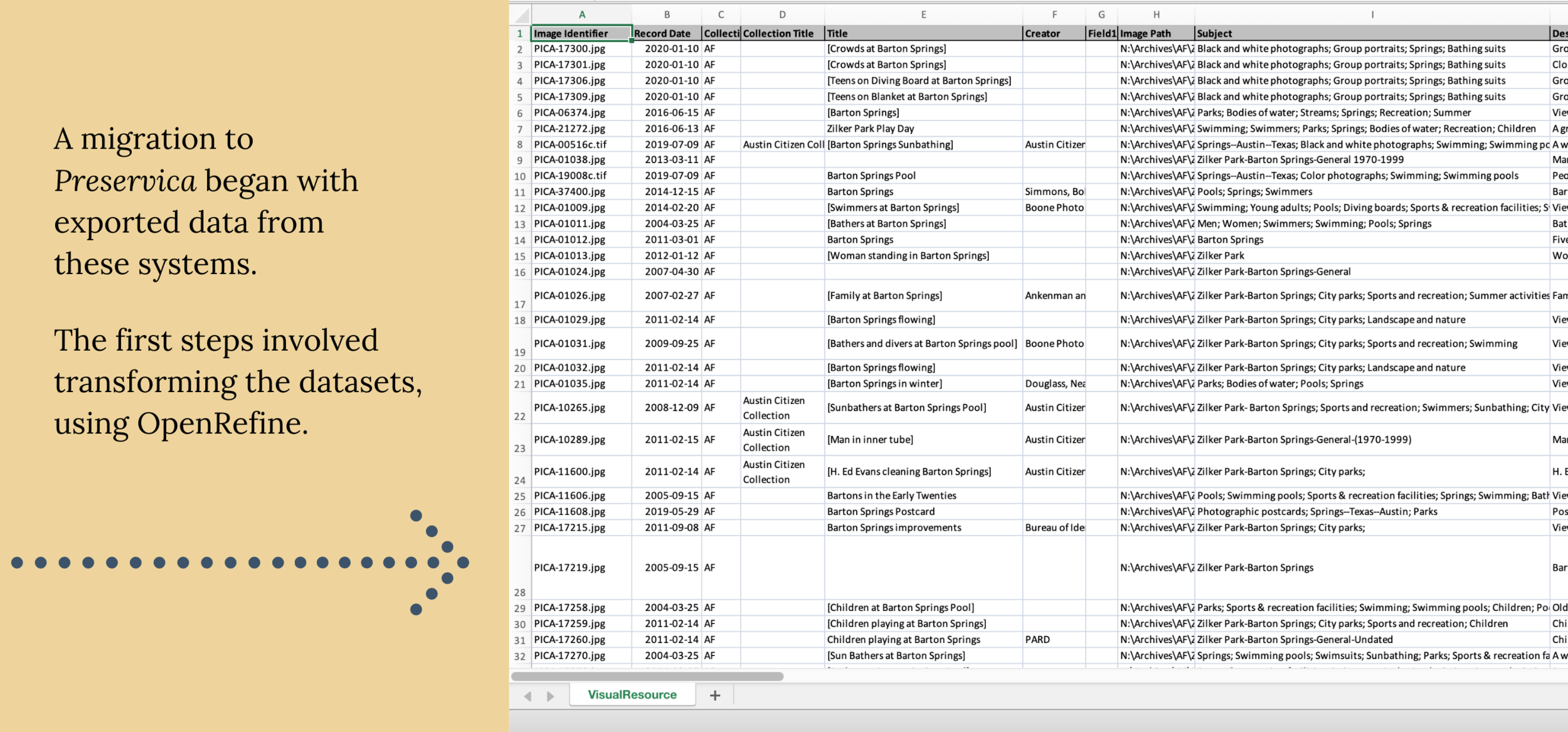
In the past, AHC staff have used different workflows and Microsoft applications to enter metadata for collection items. The migration to Preservica has involved transforming those entries into high quality metadata in XML format. The project will culminate with ingesting item-level metadata — paired with a corresponding digital surrogate or born-digital file — for over 14,000 items. I have been assisting with the migration, as a digital archives volunteer, for about a year.
This page presents contextual overviews in addition to specific work examples, describing my experience with three phases of the migration project.
Metadata Transformation
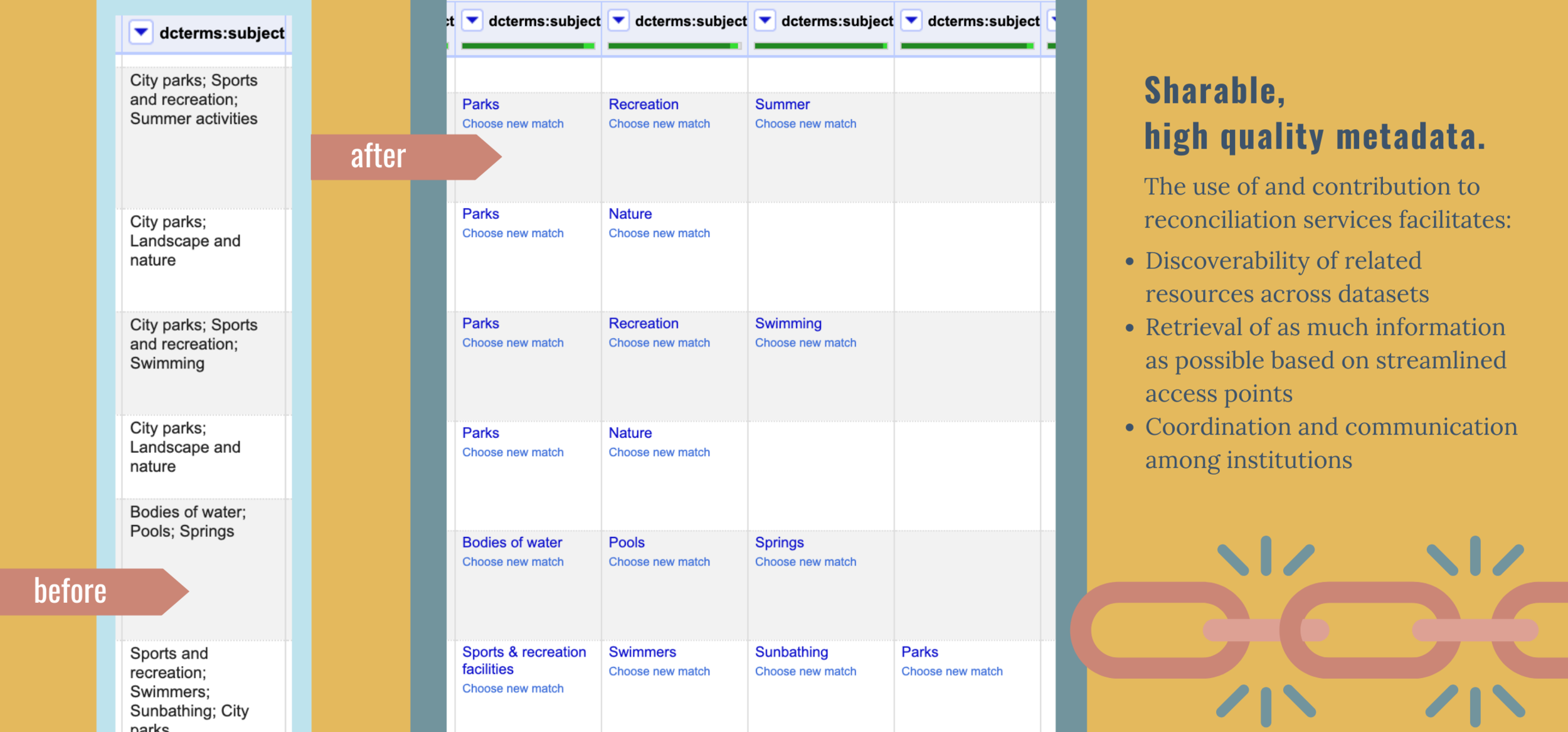
The migration project began with transforming legacy metadata. This process consisted of crosswalking an in-house element schema to qualified Dublin Core (DC), cleaning up messy metadata, and reconciling descriptive metadata to controlled vocabularies. The slides below provide an overview for this first phase of the project, which relied strongly on OpenRefine — an open-source, data-wrangling application that is popular in the archives profession. The sections following the slides present examples of specific contributions I made at this project stage, by enhancing workflow documentation and developing automation methods for increasing efficiency in OpenRefine.







Enhancing Workflow Documentation

To get started, AHC staff provided me with workflow documentation that was in early stages of development. I often took initiative to contribute to these documentation efforts. For example, I created an element set map to elucidate instructions.
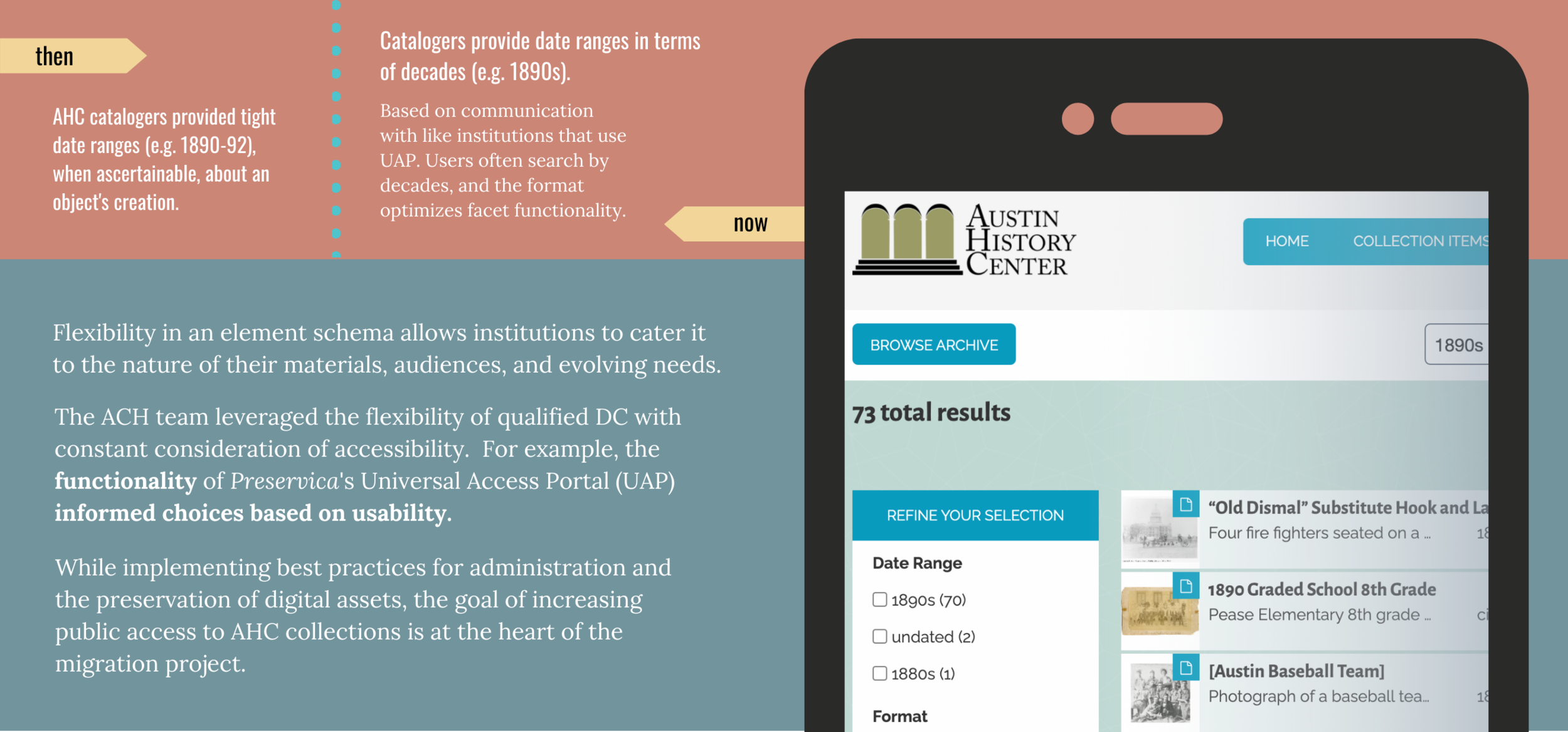
The original document mentioned that spreadsheets, provided to volunteers, had columns based on the outdated metadata elements. Next, the document: (1) presented a data dictionary for the DC elements that the AHC would now implement in Preservica, and (2) described the reconciliation of metadata entries to controlled vocabulary, as relevant to each DC element.
I addressed a gap in these instructions by recognizing tacit knowledge among AHC staff about the in-house elements and how to best map them to the DC schema. I added a table that mapped the DC schema to common elements from the outdated databases, which I was familiar with from my earlier experience at the AHC as a digitization volunteer. In addition to the map, I added instructions that described the task to: (1) rename column headers to DC terms, and (2) delete entire columns for obsolete elements and expected metadata loss. My goal was to offer an anchoring guide to volunteers, removing guesswork in choosing appropriate DC elements and increasing standardization for transformations in OpenRefine.
Increasing Efficiency: OpenRefine & GREL
Click to expand.
The AHC team used OpenRefine to prepare metadata for over 14,000 digital assets. Because OpenRefine limits the number of records you can see at a time, the exported data was separated into smaller datasets and distributed among volunteers and staff. The better we could leverage automation methods in OpenRefine, the more efficiently we could chip away at the thousands of records.
At the onset of the project, I had novice experience with OpenRefine, understanding basic features such as faceting, clustering, reconciliation, and editing cells. I taught myself how to construct advanced Google Refine Expression Language (GREL) expressions by referring to OpenRefine’s documentation.
The infographic on the left presents an example of a complex GREL expression I wrote based on project needs. Volunteers and staff could apply this GREL expression in their work to save time. I enjoy looking for ways to improve team efforts, and going beyond expectations of my assignment whenever I can make higher value contributions to a project’s success.
XML Preparation
After cleaning up metadata in OpenRefine, the AHC team needed to export each project in XML format. Preservica’s ingest workflow would require sidecar .metadata files (in XML) to be paired with two images (one for preservation and another for access) per digital asset.
This phase of the migration entailed two parts. The slides below present an overview of Part 1 — using OpenRefine’s templating exporter to write metadata into a XML file with customized specifications. Following the slides, I discuss Part 2 — splitting the OpenRefine export into separate XML files — as well as how I used Ruby and presented demos to help with the workflow.






Automate XML Split
As mentioned in the last slide above, the XML export from each OpenRefine project resulted in a single XML file, combining XML records for all digital assets from that project. Therefore, the next steps for the migration project were to:
Split each exported XML file into separate XML files (one per digital asset)
Use a digital asset’s UID as the filename for each split-out file, rather than basing the filename on the exported file
Rename the file extension for the split-out files, from .xml to .tif.metadata
This workflow involved using Ruby, and I took the opportunity to learn about scripting. The AHC team prepared a pair of scripts for steps 1 and 2. For step 3, they used a find and replace method with AdvancedRenamer. After studying the AHC’s scripts, and looking into Ruby methods, I found a way to streamline the workflow using Ruby. The image below shows how I adapted the original script designed for step 2 so it could also cover step 3.
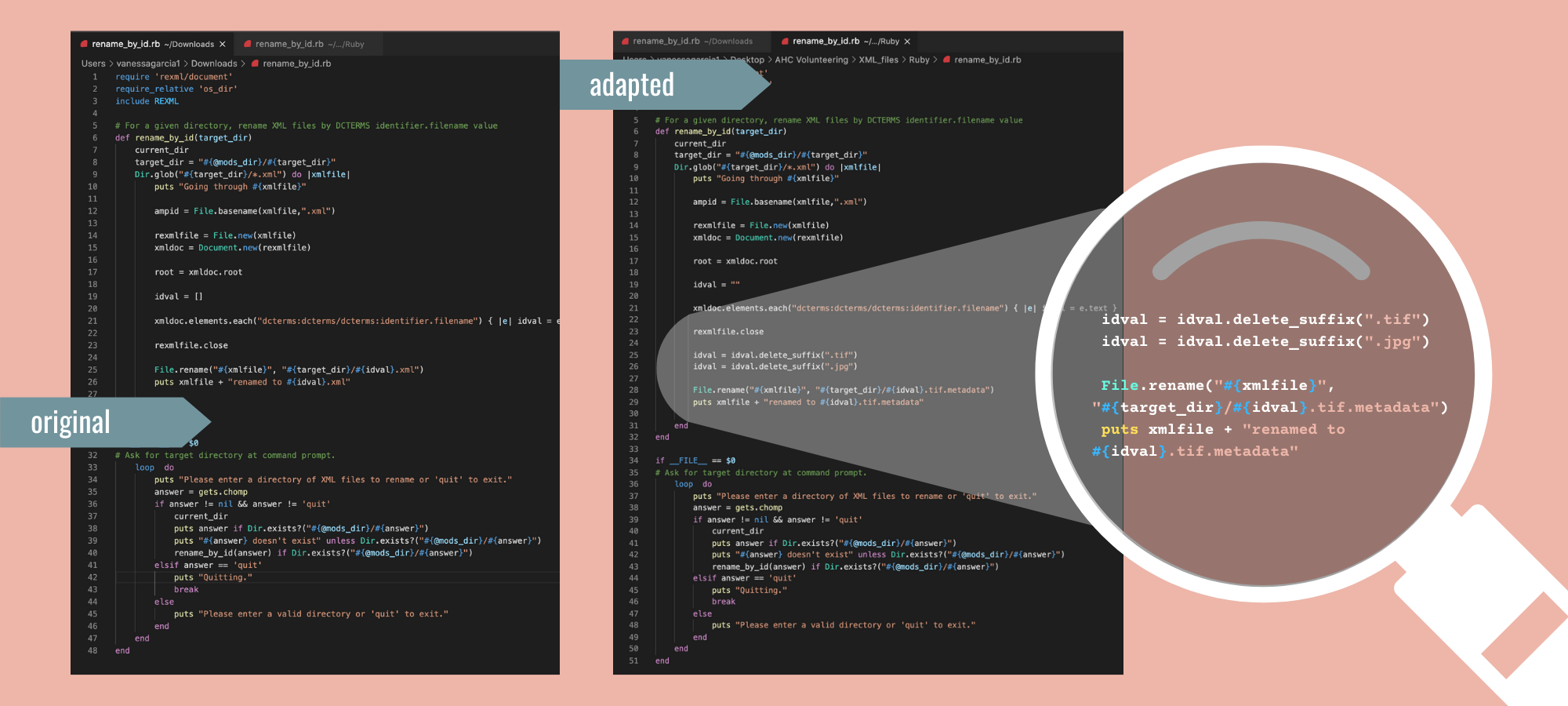
Troubleshooting & Presenting Demos
The AHC team often presented resources to each other as they worked on different stages of the migration project, and they invited me to present a demo about the XML split process.
In addition to a video about installing Perl on Macs, I created a demo (embedded to the right) considering audience-specific needs and experience levels that range among volunteers and staff. Applying my experience in education, I included examples of troubleshooting and teachable moments in the videos while staying concise.
Ingest & Takeaways
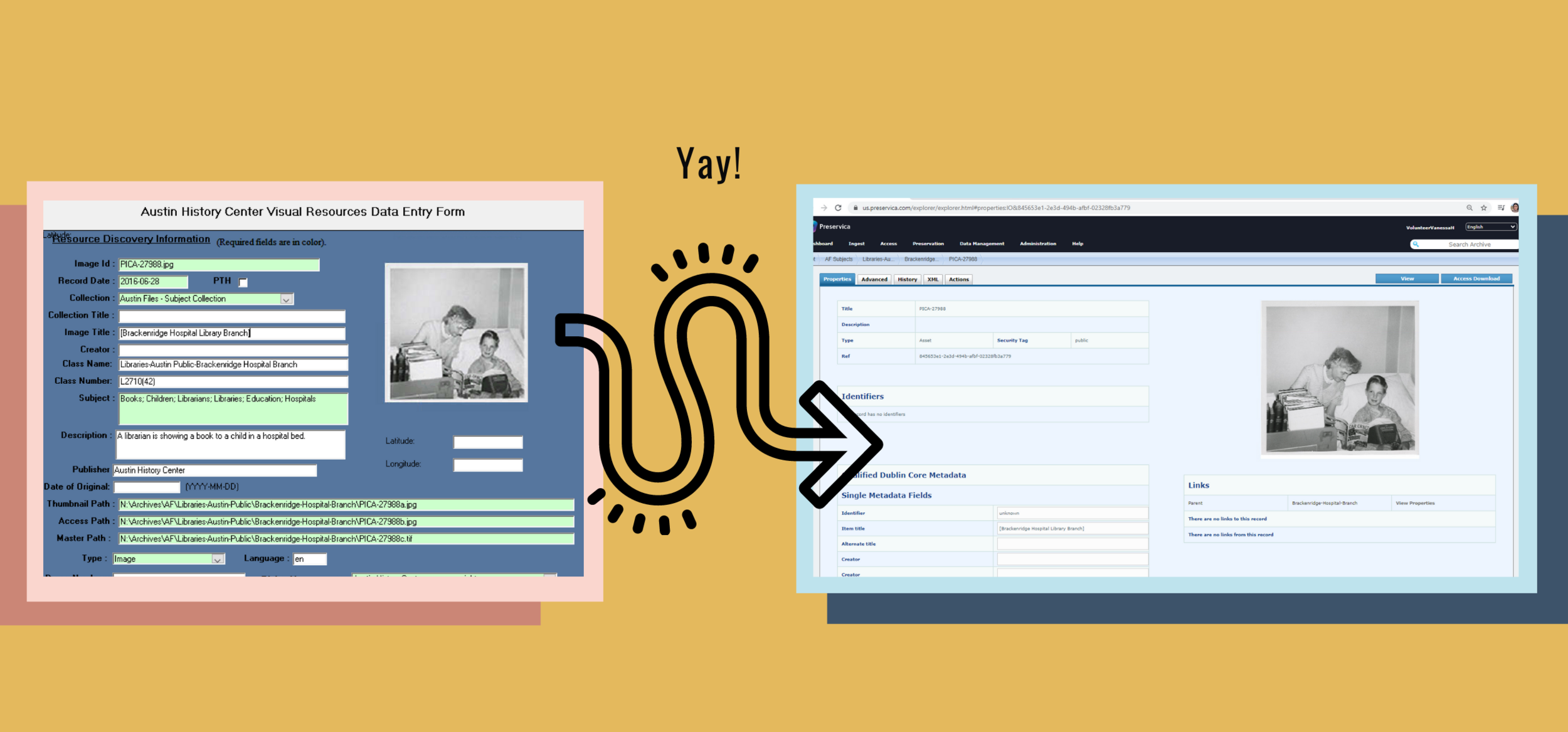
With Preservica, ingest can be very straightforward. As you will see in the slides below, the previous phases of this project yielded the necessary metadata files for its functionalities. The AHC team prepared Submission Information Packages (SIPs) by selecting the correct images from a pool of files, which called for a keen attention to detail. Once accomplishing all of this, ingest into Preservica was as easy as “drag and drop.”
Ingest is the last migration phase I have worked on and, below the slides, I discuss takeaways from my overall experience. I have built a repertoire of skills during this project that I can use beyond it, understanding that adaptability is key for leveraging digital archives tools. And ultimately, the success of digital archives projects depends on “big picture” project strategies more so than on specific technical skills.






Beyond Preservica: Adaptability
Through my experience with Preservica and the AHC’s specific migration needs, I have built skills that I can apply towards different challenges and software. For example, I recently adapted the previously discussed Ruby script to assist the University of Texas Libraries Human Rights Documentation Initiative (UTL HDRI) with its migration to UTL DAMS. In this case, the problem was that some XMLs had missing or incorrect UIDs in their metadata content. I adapted the script to pull UID values from each XML filename and insert it into the XML content within the identifier element.

Having used other software related to archives, whether proprietary or open source (OSS), I understand that a commonality is their frequently changing functionalities. For example, the AHC will soon transition to Preservica’s newly developed OPEX (Open Preservation Exchange) ingest workflow. In a different project, in which I archived tweets from @UTiSchool Twitter account, the institutional repository was in the process of migrating to a DSpace excursion instance. This project also depended on the Social Feed Manager OSS, and was subject to Twitter’s terms of service based on its Developer API. A common lesson, from such projects, is that it is helpful to use interoperable metadata schemas and sustainable file formats to increase the reliable, accessible, and potentially permanent preservation of digital objects.
Community Resources & Big Picture Strategies
“Constructing digital archives is a continually fluctuating and evolving process; as technology advances, the need to optimize the accessibility of an archive will however persist. Essentially, the preservation of digital archives is a community effort that necessarily involves multiple organizations, institutions, and individuals in order to leave a well-rounded account of images and information for future generations.” — ANON, Photography Collections Preservation Project
A crucial lesson I learned during this project came from the example set by the AHC’s digital archivist. She recognized unique skills and interests that different team members brought to the table, delegated with trust, and encouraged curiosity. I worked on a small part of the overall migration project, which involved AHC and Preservica staff members, several volunteers, City of Austin IT technicians, and consultation with digital archivists from other institutions. Her leadership demonstrated how knowing your resources, and effective project management, are key to successful digital archives efforts.
Digital archivists face technology’s changing demands in addition to a range of responsibilities such as appraisal, acquisition, and reference services. Like other projects I have worked on, the AHC migration brought up a question of how much time digital archivists should invest in learning to script on the job. There are a range of resources available on coding in the context of archives (communities like ConCode, webinars by institutions like TDL, web channels and documentation that unpack code libraries). Paired with strong leadership, I have learned how effective documentation can benefit workflow just as much as —if not more than— automation. This project brought me the opportunity to practice documentation strategies (such as those bulleted to the right) that can largely improve project efficiency.
